.jpg)

A deep research API for agents might once have been considered a specialized tool, but today it's become the backbone of the $12 billion AI agents industry, according to The Business Research Company report. These agents rely on high-fidelity data from deep research APIs to function as true autonomous researchers rather than mere LLMs.
However, to get accurate, non-hallucinated results, you need to use the best search API you can find. It needs to have low failure rates, per-record costs of only a few cents, sub-second latency, and broad coverage of data sources.
This article covers both: APIs that perform deep research natively by browsing, synthesizing, and reasoning across sources, and APIs that power deep research workflows by providing the structured, authoritative data layer that agents depend on when web search alone isn't precise enough.
What is a deep research API?
A deep research API is a programmatic interface that understands complex objectives from prompts, plans a multi-turn investigation, and synthesizes information from large datasets. In essence, deep research APIs act as the brain of AI agents operating on the live web.
As a result, deep search APIs now dominate the AI agent market. They’ve reached this point by going through a four-stage evolution:
- Stage 1: Keyword RAG. This was mere retrieval-augmented generation. The agent searched a static database for specific keywords and returned the closest match.
- Stage 2: Semantic search. The agents became assistants. They understood intent through vector embeddings and located matches even if keywords didn’t fully match.
- Stage 3: Browsing agents. This stage of development allowed the agent to read pages in real time and access links. However, it still got stuck in loops.
- Stage 4: Agentic deep research. We are now at the point where agentic search APIs conduct multi-step autonomous retrieval. The API creates a plan, runs a parallel search, cross-references facts, and synthesizes reports before the LLM receives the results.
Research APIs can now be built differently, depending on the tasks. The market has been split into three categories:
- General web-only APIs: they have the lowest cost per query and are designed to autonomously plan, browse the web, analyze, and generate reports. Some good examples include Exa, Tavily, and You.com.
- Proprietary domain APIs: they can access hidden data on the web, which makes them ideal for specific, pre-vetted information found in academic databases and RSS feeds. Valyu, Firecrawl, and Gemini are examples of proprietary domain APIs.
- Structured B2B APIs: these are the most accurate APIs that provide clean JSON schemas. They are primarily used for retrieving data on companies and employees. Some of the best examples of this are Coresignal and ZoomInfo.
Evaluation criteria
Here are the criteria I’ve used for evaluating the leading research API picks:
- Data source coverage: I’ve chosen the APIs based on what data sources they cover. Each falls into one or more of the three categories I’ve mentioned. The best APIs have hybrid coverage, meaning they go through proprietary databases and gated content.
- Agent-native interface quality: a high-quality agent-native interface enables the AI agent to express intent in plain English, while the API handles the technical translation. The API must accept natural language prompts and return data in a structured format.
- Output format: the API shouldn’t send raw HTML back, but structured records with 300–500+ fields in clean JSON format. This significantly reduces the cost because you’re spending fewer tokens.
- Integration complexity: native MCP support and trace visibility are a must so that the API can provide a trace of its reasoning. Consequently, the agent will be able to show why it has reached its conclusion.
- Scale and data freshness: the API needs to access fresh data while maintaining temporal precision (that is, viewing the data's state at a specific time). This allows it to provide a verified historical record.
8 best deep research APIs and supporting APIs for AI agents
Below is the full list evaluated in this article, along with the key details on each.
How to read this list
Not every API here works the same way. Some browse and synthesize from the open web in real time. Others access gated academic, financial, or proprietary sources. A third group – including Coresignal – doesn't research in the traditional sense at all. Instead, they supply the structured, pre-verified data layer that agents need when web search isn't precise or reliable enough for high-stakes B2B tasks. All three approaches are relevant to building capable research agents. The right choice depends on what your agent is actually trying to find, and how much it can afford to trust an unstructured web result.
1. Coresignal – best for B2B agent intelligence
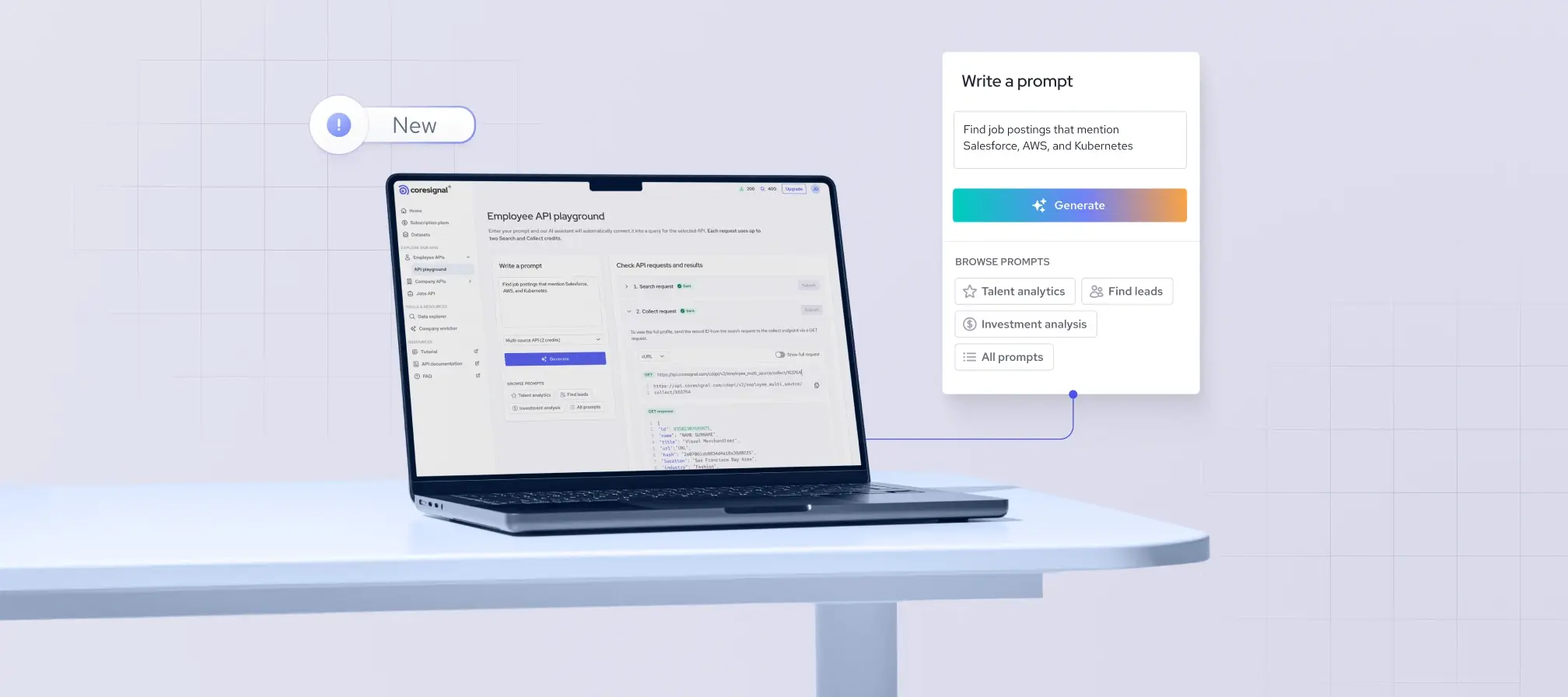
Most deep research failures in B2B contexts don't come from weak synthesis – they come from weak source data. Outdated company records, unverified employee profiles, and unreliable job signals make even the best reasoning model produce confidently wrong answers.
Coresignal sits at that layer. Its Agentic Search API accepts natural language queries and returns structured, verified records across 4.5 billion company, employee, and job posting data points – without requiring SQL, schema mapping, or data cleaning on the agent's side. Rather than browsing and summarizing the web, it gives agents direct access to a pre-verified B2B data infrastructure, making it particularly valuable for lead generation, recruitment automation, investment research, and competitive intelligence workflows where accuracy isn't negotiable.
- Data coverage: 4.5 billion+ company, employee, and job posting records
- Output format: JSON, JSONL, CSV, Parquet
- Pricing: credit-based model, plans start at $49/month
Agentic fit
Coresignal is best for agents that need verifiable, structured B2B facts rather than open-web synthesis. It is not designed for content discovery, real-time news, or broad web research, but for agents where the quality of the underlying data determines the quality of the output, it fills a gap that web search APIs cannot.
// Find senior engineers at fintech companies in New York
curl -X 'POST' \
'https://api.coresignal.com/cdapi/v2/agentic_search/reasoning' \
-H 'accept: application/json' \
-H 'apikey: {API key}' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "Find heads of engineering or CTOs at European fintech companies who have US work experience.",
"return_data": true,
"allow_clarification": true,
"limit": 20
}'2. Valyu DeepResearch API – best for proprietary academic and financial data

Valyu stands out for its access to 36+ proprietary data sources. It’s made for gathering technical and financial data that’s usually hidden behind paywalls and in complex databases.
Valyu is capable of indexing data sources like USPTO patent databases, real-time financial filings, and academic journal repositories. Naturally, it doesn’t return just links but also comprehensive reports or synthesized JSON.
This API for AI search is designed for medical and scientific research, financial due diligence, and tracking global litigation trends and patent landscapes.
- Data coverage: 36+ premium sources like PubMed, SEC EDGAR, and FRED
- Output format: documents in several formats, XLSX spreadsheets, JSON
- Pricing: flat per task rate; plans start at $29/month, but there’s also a Pay As You Go option
Agentic fit
Valyu is made for agents that need to conduct specialized, professional research. It’s not for general common knowledge queries or social media monitoring.
3. Firecrawl Agent Endpoint – best for schema-first web extraction at scale
Firecrawl is a data API for AI agents that focuses on turning web data into machine-ready formats. It's the standard industrial-grade choice for developers who need to create their own datasets or monitor a large number of sources simultaneously.
Firecrawl works on a schema-first extraction philosophy. It has a parallel-agent architecture, meaning it launches multiple agents to map the entire domain. It works with Pydantic and Zod schemas and uses a curated index to prioritize authoritative sources.
It’s designed for automated content aggregation, monitoring price changes and feature updates, and building agents that need to learn from specific niches.
- Data coverage: Near full web coverage
- Output format: Markdown, JSON, HTML, raw HTML
- Pricing: Tiered usage-based; plans start at $19/month
Agentic fit
Firecrawl is designed for developers who need to build data-intensive agents. It’s not really suitable for academic synthesis or common-sense questions.
4. Exa – best for search over web content
Exa was developed for embedding-based semantic search; in fact, it was one of its initial pioneers. Instead of matching text exactly, it uses a neural index to understand a query’s conceptual relevance, which is what makes it so beneficial for grounding LLMs and agent workflows.
Exa also offers Zero Data Retention (ZDR), ensuring queries are never stored, and delivers results with sub-second latency.
This data API for AI agents is ideal for RAG pipelines that need conceptual relevance, technical and code discovery, and broad web trend monitoring.
- Data coverage: broad open web, 30+ billion indexed pages
- Output format: JSON
- Pricing: credit-based model; plans start at $1 per 1k requests
Agentic fit
Exa is best suited for RAG pipelines and agents that need to perform fast searches on the open web. It’s not for the ones that need structured, verified enterprise records.
5. Tavily – best for LangChain/LlamaIndex-native workflows
Tavily is made for agents, not browsers. Unlike legacy search APIs that return raw HTML and SERP clutter for humans, it delivers the structured data AI agents actually need. That’s why Tavily is generally considered the default for developers working in agentic frameworks like LangChain and LlamaIndex.
It’s natively integrated into most major AI orchestration libraries and features structured, clean, and citation-ready JSON. It uses the MCP ecosystem and offers 1,000 free monthly credits through its free plan.
The Tavily API is designed for RAG-backed copilots, multi-tool orchestration workflows, and site mapping and crawling.
- Data coverage: full public web, optimized for news, real-time events, and tech docs
- Output format: JSON
- Pricing: credit-based model; plans start at $30/month or $0.008/credit
Agentic fit
Tavily is ideal for developers building LangChain or LlamaIndex-native apps, but it’s not for high-volume, deep data scraping.
6. You.com – best for high-accuracy general web research with verified excerpts
You.com is designed for agents that need to do high-accuracy web research and have to back up each of their claims. Most search APIs are designed for speed, whereas You.com is made to combat AI hallucinations.
This API provider stands out for its sophisticated verification and citation process for general web indexes. On the SimpleQA benchmark, the standard Search API achieves 92.46% accuracy, with the Deep Search endpoint reaching 95%+.
You.com is good for fact-checking and content verification, high-fidelity executive summaries, and supporting RAG workflows.
- Data coverage: full public web
- Output format: JSON
- Pricing: credit-based model; plans start at $5 per 1k calls or $1 per 1K pages
Agentic fit
You.com is ideal for enterprise agents and RAG setups that require factual truth on the open web. It’s the best choice if you need minimal hallucinations. However, it’s not great for pulling large numbers of personnel variables for cold outreach or chaining complex browser actions.
7. Google Gemini Deep Research API – best for exhaustive, synthesis-heavy reports
Google has made a notable push into the enterprise agent market with its Gemini Deep Research agents, accessible through its Interactions API. With the help of Google's advanced reasoning models, the API is an asynchronous research coordinator that can write professional, multi-page reports.
Its standout feature is collaborative planning – before execution, it generates a full research strategy that users can review and refine. It also has two specialized operational tiers: Deep Research, optimized for speed and efficiency, and Deep Research Max, designed for maximum comprehensiveness.
Gemini Deep Research is well-suited for detailed market analysis, financial due diligence, and building structured executive summaries.
- Data coverage: unmatched public web coverage thanks to native Google Search infrastructure
- Output format: JSON, Nano Banana
- Pricing: metered through paid tiers of Gemini API; prices vary
Agentic fit
Gemini Deep Research API is ideal for enterprise pipelines that need comprehensive, multi-step synthesis and highly structured long reports. It’s not made for instant conversational lookups.
8. Linkup – best for research agents that need live web context
Linkup is a production-grade web search and research API used by McKinsey, KPMG, and Cohere. Its most relevant capability for research agents is the dedicated /research endpoint – an asynchronous deep research API that conducts multi-step web investigation, synthesizes findings across sources, and returns cited, structured outputs. It ranks #1 on SealQA-0 for web-grounded research accuracy, and operates a proprietary AI-native web index rather than scraping SERP results. Native integrations include LangChain, LlamaIndex, CrewAI, n8n, and MCP.
- Data coverage: proprietary AI-native web index across the open web
- Output format: JSON with source URLs and structured snippets
- Pricing: usage-based; freemium tier available
Agentic fit
Linkup is best for agents that need accurate, source-attributed research on complex multi-source queries, particularly where the async Research endpoint adds value over single-pass retrieval. Not designed for structured B2B data or domain-specific records outside the public web.
Main deep research APIs use cases
Each search API covered in this article is built around a distinct data model and collection methodology. Here's how that translates to specific use cases.
1. Building agentic search tools with a chat interface
The API powers a full conversational assistant. The chat interface of the agentic search tool is the frontend, while the deep search API operates in the background in a continuous loop. There’s no need to open multiple tabs because the agent reads and presents synthesized answers in a conversational manner.
2. Building smart research agents
The API enables the AI agent to plan complex research tasks, break them into sub-tasks, conduct deep web scrapes, bypass paywalls, and compile large reports. These smart research agents solve the issue of scalability because one human can manage dozens of them.
3. Sales and GTM intelligence
Where traditional B2B sales rely on static databases, deep research APIs let sales teams gather highly specific data in real time. This solution offers hyper-personalized outreach, allowing a sales rep to easily generate a highly personalized email rather than using generic templates.
4. Autonomous analyst tools
Autonomous analyst tools can automate the grunt work of gathering finance data and synthesizing findings. The API is connected to financial data streams and the web. It can monitor the market and track competitor movements, and even flag opportunities or anomalies.
5. Vertical copilots
Generic AI assistants struggle in specialized industries, but API-powered copilots are deeply integrated into their markets and offer very high accuracy and compliance.
When not to use a deep research API
While useful in many cases, it needs to be addressed where deep search APIs aren’t helpful. Here are the main instances where you don’t need to use a deep research API:
- If you need a response to your query in seconds. You need a standard search API because a deep search one is optimized for synthesis, not speed.
- If you have to access authenticated pages or internal documents. In this case, you need a browser automation layer like Playwright or Browserbase.
- If a single web page lookup can answer your question. A deep research API here is costly and unnecessary.
Final thoughts
The gap between a good API fit and a poor one shows up quickly in cost, accuracy, and cleanup time. General web APIs handle open-web synthesis well, proprietary-domain APIs unlock paywalled sources, and structured B2B APIs deliver the precision that business intelligence actually requires.
No single API is suitable for every use case. The right choice depends on what your agent does and what data it needs. For agents built around verified company, employee, and job data, Coresignal's Agentic Search API converts natural language prompts directly into structured queries across 4.5 billion professional records – no SQL or schema mapping required.